Denial of Service (DoS) attacks took down both Sony’s Playstation Network (PSN) and Microsoft’s XBox Live (XBL) on Christmas day – turning the joy of Christmas in to frustration and disappointment for anyone who received a new game for Christmas. As of 12/26, XBox was largely restored, while Playstation was still at least partially offline, with PS3 access intermittent at best, the Playstation Network website “unavailable due to scheduled maintenance”, and PS4 access completely unavailable.
Knowing in advance that threats had been made of a DoS attack on Christmas day, both companies had plenty of time to prepare, yet they either chose to ignore the threats or take insufficient precautions, leaving their staff scrambling, and their customers frustrated.
Here is a simple method that could have been used to prevent the whole fiasco.
Table of Contents
How Global, Distributed Services are Designed
Let’s start with some relevant background information.
- Service: Something you use, such as e-mail or shopping. Applications are often called services.
- Server: A high-capacity PC, with lots of memory and many CPUs, that runs an application to provide a service. An application is the code running on the server.
- Network: A network connects consumers to businesses (B2C), businesses to other businesses (B2B), or peers (P2P). The internet is one, big network.
Data Centers
Global services such as PSN and XBL run on hundreds (or thousands) of servers that are grouped in large, secure, centralized facilies called data centers.
Data centers are located logically and geographically to provide the best performance to specific regions of the world, while providing some redundancy in the event of a facility-wide failure.
For regions where there are millions of customers, there might be multiple data centers within a single region, that provide redundancy and performance based on geographic diversity.
Domain Name System (DNS)
When you, as a PSN or XBL customer, connect to these services, you connect using a specific name, such as “playstation.com”. You don’t see this name, because it”s embedded within the configuration of your game console, unless you access their website using a browser. When you fire up your game console, it automatically connects to these services, and communicates with the underlying servers, to log you in, obtain updates, and allow your gamer friends to connect to and communicate with you online.
Domain Name System (DNS) resolves the name “playstation.com” to a network Internet Protocol (IP) address, and your Playstation or XBox then uses the IP address to make a connection to the appropriate servers.
Each world-wide region has its own domain name, such as “playstation.com” for North America, versus “playstation.co.uk” for the United Kingdom. Each name has its own IP address, that then routes your console to the respective data center for that region.
Internet Assigned Numbers and Worldwide Regional Registries
Internet Protocol (IP) addresses are assigned by the Internet Assigned Numbers Authority (IANA), who delegates ranges of addresses to each of the worldwide regional number registries, who then make specific IP address assignments, usually in large blocks, to the tier 1 providers (such as AT&T, Time Warner, Verizon, and Cogent in the US).
http://www.internetassignednumbersauthority.org/numbers
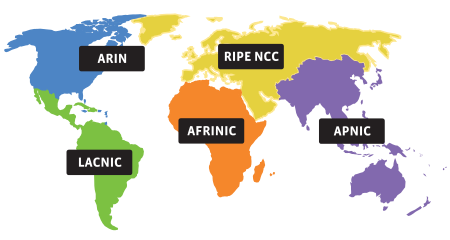
(Graphic courtesy of IANA)
Tier 1 providers then make smaller allocations to tier 2 providers, as well as companies such as Microsoft and Sony, for their data centers and associated networks.
If the source and destination are within the same region, for example, if you live in North America, fire up your Playstation, and it connects to a North American data center, it’s reasonable to assume that both your home network’s IP address as well as the data center IP address were both assigned by ARIN. There are a few exceptions to this, but in general, this rule works as described.
In general, the first number of your IP address is tied to the regional registry, and therefore the region.
My IP address is 76.186.x.x (the last two numbers are hidden for security reasons). Searching for my IP address on the ARIN website yields the following information:
Network Net Range 76.184.0.0 – 76.187.255.255 CIDR 76.184.0.0/14 Name RRACI Handle NET-76-184-0-0-1 Parent NET76 (NET-76-0-0-0-0) Net Type Direct Allocation Origin AS Organization Time Warner Cable Internet LLC (RRSW) Registration Date 2006-07-26 Last Updated 2007-03-12 Comments RESTful Link http://whois.arin.net/rest/net/NET-76-184-0-0-1 See Also Related organization’s POC records. See Also Related delegations.
The information provided is regarding Time Warner Cable, my internet provider. Time Warner also does business as “Road Runner Cable”, thus the reference to “RR” in the organization’s handle.
You can see that my IP address, starting with 76.186, is part of a rather large range starting with 76.184.0.0, ending with 76.187.255.255, identified by its CIDR (Classless Inter-Domain Routing) notation of 76.184/14.
The “/14” indicates 14 subnet bits of the 76.184 address are fixed. The simple explanation is that /14 allows for a range of 76.184 through 76.187 to be included in the assignment.
The more complex answer is that each “octet” has 8 bits, so the /14 (meaning 14-bit) subnet mask would be 255.252.0.0, keeping the first octet number 76 fixed (255 subnet mask covers the first 8 bits, keeping them fixed), while allowing for the two least significant bits of the second octet, 184 to be excluded. 184 in binary is 1011 1000. 252, or 1111 1100 also allows 1011 1001 (185), 1011 1010 (186) and 1011 1011 (187) to fall within the same subnet.
Clicking on the parent link for NET-76-0-0-0 yields information about the parent network block, and the provider who allocated 76.186 to Time Warner:
Network Net Range 76.0.0.0 – 76.255.255.255 CIDR 76.0.0.0/8 Name NET76 Handle NET-76-0-0-0-0 Parent Net Type Allocated to ARIN Origin AS Organization American Registry for Internet Numbers (ARIN) Registration Date 2005-06-17 Last Updated 2010-06-30 Comments RESTful Link http://whois.arin.net/rest/net/NET-76-0-0-0-0 See Also Related POC records. See Also Related organization’s POC records. See Also Related delegations.
Notice that there is no parent listed, and the Net Type is “Allocated to ARIN”, so this is a top-level assignment made by IANA to ARIN. The CIDR notation is 76/8, meaning that this range covers 76.0.0.0 through 76.255.255.255, which includes the Time Warner allocation, 76.184/14, which includes my IP address, 76.186.x.x/32.
Any IP address starting with “76” belongs to ARIN, servicing North America, so any 76.x.x.x IP address probably falls within North America.
Routers
Routers “route” traffic on the internet by forwarding chunks of data, called packets, between network segments. Routers look at the source and destination IP address of each packet, to determine where to send it next. Often, packets are forwarded by several routers, to get from the source to the destination.
IANA provides high-level network routing information based on allocation to the regional registries, who then provide specific routing information for each allocated netblock.
Within a provider or company’s network, an allocated netblock can be broken in to multiple subnets, so it’s up to the provider or company holding the allocation to provide specific routing information for each IP address within the netblock.
At a high level, every IP address on the internet needs to be able to communicate with every other IP address.
The internet is composed of several, large, “backbone” internet providers that are connected to each other at multiple peering junctions. Companies such as AT&T, Verizon, and Cogent own these large backbone networks in North America and Europe, while in some countries, the internet “backbone” is owned by the government.
Each router that services a peering junction between these backbones includes the high-level routes provided by ARIN and other registries, as well as more specific routing information about how to forward the packet within its own network.
When sending data from your Playstation to one of Sony’s servers in a Sony data center, the traffic is routed from your house, to your neighborhood distribution point (Cable, DSL, and Fiber all use different technologies and topologies), to your regional distribution point, then on to your provider’s backbone, through a peering junction to Sony’s provider’s backbone, and then finally on to the Sony network, where it’s routed to the data center where Sony’s server is located. The response packets follow the opposite path.
Firewalls
Firewalls enforce “the rules of the road”, so to speak, to ensure that only public-facing services are accessible on the internet, and that they are accessed using the appropriate method.
Firewalls block inappropriate or improper connections, based on a set of rules configured to allow traffic based on source IP address, destination IP address, connection endpoint (also called a TCP/IP “port”), or other criteria.
Specific services use specific well-known TCP/IP ports (endpoints) based on a set of rules called RFCs (Requests for Comment), that allow multiple vendors and service providers to agree on a single standard, rather than have different standards for each vendor, provider, or region.
Most data on the internet is transmitted using HyperText Transfer Protocol (HTTP), that encompasses HTML (formatted web pages) as well as raw XML data used to display web pages or transfer information between servers. HTTP servers, when NOT using encryption, always listens on port 80, while encrypted HTTP servers always listen on port 443.
A firewall sitting between the routers and the servers might have a rule to allow any source IP address, connecting on port 80 or 443, to the specific destination IP addresses (servers) that host public-facing services and content.
A Home Network “Router” is a Firewall
Most people have what they call a “router” at their house, that allows multiple devices inside the home to share a single connection to their provider’s network, and ultimately access various services on the internet.
These devices are actually firewalls!
They perform Network Address Translation (NAT), allowing each device on the home network to “share” the public-facing, provider-assigned address to talk to various servers on the internet. NAT maintains a list of who is talking to what, and ensures that return traffic sent FROM the internet servers are sent to the correct internal device on the home network.
Home “routers” (firewalls) also maintain a list of rules about traffic flowing between the home network and the internet. Usually by default, there is a single rule allowing outbound access for common services such as HTTP, and secure HTTP (HTTPS). Some PC games and Voice over IP (VoIP) services require incoming connections, so most routers also allow advanced users to create additional rules for these types of services. If you run a game server at your house, or you use an internet-based VoIP service, you may already have some of these additional rules configured on your router.
For all practical purposes, you can think of a home network “router” as a one-way trapdoor, allowing PCs, game systems, and other devices on the home network to originate a connection to services on the internet, while preventing inbound connections originating from the internet from connecting to the home devices. So you can connect to Google any time you want, but Google can never connect to you, because there is no rule on your router to allow it.
Intrusion Detection and Prevention (IDS/IPS)
Most data centers, in addition to firewalls whose job is to regulate traffic, also employ Intrusion Detection Systems (IDS) and / or Intrusion Prevention Systems (IPS).
The job of IDS/IPS is to detect suspicious traffic and either alert (IDS) or stop it (IPS). In the case of IPS, the traffic is simply dropped without a response to the sender.
IDS/IPS, in addition to signatures for specific types of malicious traffic, employ behavioral analysis to try to detect and stop malicious traffic. For example, scanning (attempting to connect) for services on a server or across servers on the same subnet might trigger IPS to drop the traffic.
In some cases, IPS can be configured to update a blacklist, which is a list of known, malicious IP addresses. Network equipment that supports black listing, can either read the blacklist directly, or in some cases, the IPS can trigger a script that updates routers and firewalls to explicitly deny traffic from these sources.
IDS/IPS is like airport security, who scans all of the traffic, and only allows traffic to pass if it doesn’t contain any obviously malicious content, and conforms to appropriate access rules.
Network Connections
A network connection usually uses Transmission Control Protocol (TCP).
A TCP connection is established via the following sequence:
- Client sends SYN (“synchronize”) packet, initiating the connection, and requesting that the server “synchronize” by sending an ACK (“acknowledgement”) packet.
- Server sends SYN-ACK (“synchronize” plus “acknowledgement”) packet, acknowledging the client SYN, and requesting an ACK.
- Server sends an ACK packet, responding to the server SYN
This is known as the “three-way handshake”, establishing the TCP connection.
Once the session is established, the server expects the client to send a request, and the server will respond, sending some data back to the client.
In reality, as long as the server and client agree on the data format, data and / or instructions can be sent in either direction!
Let’s consider the following scenario:
- Client initiates a connection
- Client reads a command (message) queue from the server
- Client executes instructions
This is functionally-equivalent to the server initiating a connection, but respects home network firewall rules.
Connections vs. Sessions
A “connection” is the function of a network. Two systems connect to each other on a network, to pass some data back and forth.
A “session” is the specific environment created for you, when you connect to a server. Keeping in mind that when you connect to a server, you connect to a well known endpoint, such as HTTP (port 80) or HTTPS (port 443). When a server receives a new connection, it creates a session for that connection, and maps the client IP address to that session. There are some additional mechanics that allow multiple PCs or game consoles to connect to the same server at the same time from ONE shared IP address, but let’s keep things simple.
Sessions usually start by asking you to log in – if you have Yahoo or Google mail, you usually have to log in at the start of the session before you read your e-mail. After you log in, the session maintains your status, such as whether you’re online, busy, or idle, as well as what game you’re playing.
When your friends get an alert, invite you to a lobby, or send you a message, this is all handled through your server session.
Remembering that home networks deny incoming connections, when you invite your friend to a lobby or send him a message, this is all handled on the server side! Your friend’s game console can’t connect directly to your game console. Each server session maintains a message queue, and the game console polls its message queue. When you send your friend a message, the servers within the network communicate to each other, and your message gets delivered almost instantly to your friend’s message queue, where your friend’s console is maintaining a connection from his house, reads the message queue maintained by his console’s server session, and pops up a message for him.
Load Balancing / App Delivery
Each server session requires a little bit of memory and other server resources, meaning, there is a limit to the number of sessions per server.
Global services such as PSN and XBL require many many servers, because they support millions of concurrent connections.
Mapping every new user to a specific server would quickly become unmanageable! How do they do it?
Load balancing, also known as Application Delivery, accepts the incoming network connection, and then routes a second, internal connection to one of several servers that are configured in a “pool”. The load balancer uses one of several algorithms to determine the least-busy server, the server with the fewest connections, or perhaps “round-robin”, where each new connection goes to the next server in sequence.
Once the connection is established, the server creates a session, and the load balancer maintains “session persistence”, sending all subsequent requests from your console to the exact same server, so that your session can be maintained on one server. If you got routed to a different server each time, you’d have several sessions across several servers! Message queuing definitely would NOT work correctly!
Load balancing allows a large number of network connections to be serviced by multiple servers that each host a group of sessions – a portion of the total number of sessions.
High Availability and Redundancy
In addition to allowing multiple servers to act as “one big” server, load balancing also provides high availability and redundancy.
High availability means that if one server fails, the load balancer automatically routes your connection to another server. If the application has been designed correctly, the new server reads your session information in to memory, and maintains your session from that point until you log out, ending the session.
Load balancers also allow for redundancy, which is the flip side of high availability. Redundancy means excess capacity that is configured and ready, in the event of a failure. Most load balancers are explicitly-redundant! A pair of load balancer devices act as a single device, providing 100% redundancy, if the load balancer fails. Some redundancy schemes include having excess capacity incorporated in to the main server “pool”, or having a separate “overflow” pool available if something fails.
Load balancing comes in two flavors: Global Server Load Balancing (GSLB), and LTM (Local Traffic Management). Various load balancer vendors may refer to these using slightly different terms, but the concepts are consistent. GSLB allows traffic to be routed to multiple data centers (Active-Active) or to provide data center failover (active-passive). LTM allows traffic to be routed to multiple servers within a data center (active-active), or to provide server failover (active-passive).
Designed correctly, YOU CAN HAVE AN ENTIRE DATA CENTER FAIL, plus some of your servers in the OTHER data center, and STILL not have any down time.
Summary – Global, Distributed Services
When you fire up your game console, it originates a connection via your home “router” (firewall) that allows the traffic to be sent to the internet. Internet routers forward your traffic to your appropriate regional PSN or XBL data center based on domain name, and its associated regional IP addresses. Services such as PSN and XBL then use firewalls, IDS / IPS, and load balancing to ensure that your connection is legitimate, remove malicious connections, and route your connection to a specific server. When you log in, messages and invites from your friends get routed to your server, and your console reads them from the server using its connection.
Load balancing provides high availability, in the event of failure, upgrades, or other environmental or technical problems.
DoS and DDoS Attacks
Denial of Service (DoS) and Distributed Denial of Service (DDoS) attacks are designed to overload a network with multiple bogus connections, or server farms with mutliple bogus sessions, in order to prevent or “deny” legitimate consumer traffic, or choke out legitimate user sessions due to lack of resources.
Let’s look at how this is done.
What is a Denial of Service (DoS) attack?
Denial of Service (DoS) means that a legitimate consumer can’t access the services in question. A DoS attack is designed to prevent legitimate access by overloading the network or server resources used to host the service in question.
Anatomy of a DoS Attack
Denial of Service is achieved by overloading network and server resources.
Network components, such as firewalls and routers, require a tiny amount of information for each unique connection. This information is maintained in a connection table, and the connection table is limited by memory available to the device.
Using valuable router, firewall, and server resources results in fewer resources available for legitimate connections.
Each connection uses memory, and moving memory blocks requires CPU resources. Thus, spamming a router or firewall with thousands or millions of bogus connections chews up resources, preventing legitimate connections from being established.
The earliest attacks were “SYN” attacks, consisting of sending multiple, random SYN packets that appear to originate from random source IP addresses. On older firewalls, this results in a connection being allocated in memory, and a SYN-ACK packet is sent to the fake source IP address, who has no idea what is going on! Meanwhile, the firewall waits for a response “ACK” packet, allocating extra resources for the fake connection until it times out.
Firewall vendors responded by having a configurable SYN timeout, that more rapidly flushed half-open connections.
Later, “Distributed” Denial of Service (DDoS) attacks consisted of an attacker compromising multiple intermediary “zombies” — PCs that had been previously compromised, each of which spams the firewall with thousands of fake SYN packets, that all appear to originate from random parts of the internet. As fast as the older firewalls could flush half-open connections, the aggregate effect was the same – legitimate connections would be choked out, and the distributed nature of the attack meant that an attacker could actually use up the victim’s internet bandwidth.
Modern firewalls block SYN attacks by having a “quarantine” memory area, that limits the number of incomplete connections. As new “SYN” packets are received, memory within the SYN quarantine area is reallocated, dropping the oldest requests. Once a valid ACK packet is received from the client, the connection is moved from the SYN quarantine area, to the main connection table. This prevents thousands or millions of “spam” SYN packets from disrupting valid, established connections by chewing up resources. Only “complete” connections get moved to the “valid” (“established”) connection table.
From a bandwidth standpoint, having multiple internet circuits prevents a single circuit from becoming saturated.
Modern, sophisticated denial attacks use zombie networks to make “real”, established connections, and then spam the server with bogus, but legitimate-looking requests.
Routing rules in the application delivery tier (load balancing tier) route certain types of requests to specific server pools based on content or formatting. For example, a game console might send an XML formatted request, while a PC or mobile handset might send an HTML formatted request. Further, the mobile request is probably looking for mobile-formatted content. App delivery might route each of these three types of requests to a separate server pool.
Because of the app delivery tier, an effective DDoS attack has to have some valid data and formatting.
The down side is that each attacking node (“zombie”) also has to maintain legitimate network connection, unlike SYN attacks that appear to originate from random addresses, allowing the victim to manually identify and block the attack one node at a time – a time-consuming, and effort-intensive process.
The Big Picture
DoS and DDoS attacks use large networks of zombie PCs to generate millions of fake requests, to completely consume firewall connections and server resources, thus “denying” legitimate traffic.
Architecture for Preventing DDoS Attacks
At a high level, differentiating traffic by geographic and logical source based on IP address, across multiple pipes, allows the app delivery tier to effectively route legitimate traffic, while defining rules preventing traffic from crossing to other pipes or server pools.
Step 1: Use Source-Based Access Policies to Region-Lock Connections
Zombie farms (large networks of compromised PCs) often exist across regional boundaries. Often PCs from Eastern Europe and Asia are compromised, because they have fewer protections than PCs in North America.
By creating regional source-based access policies, traffic originating from RIPE or APNIC regions is prevented from reaching the ARIN region. Further, traffic from RIPE or APNIC can’t be used to DDoS each other.
Step 2: Maintain Multiple Network Connections
From a logical standpoint, direct access to your data center is facilitated by direct connections from the major providers:
- AT&T
- Verizon
- Time Warner
For a service provided almost exclusively to home networks, these three companies service over 90% of your connections in the US.
Starting with multiple independent connections gives you the advantage over an attacker, having to launch multiple attacks using sources on multiple networks, as opposed to being able to overrun a single connection using a single attack, using sources from multiple networks. At best, an attacker with a mass of zombies on one provider’s network can ONLY clog that one pipe.
Again, source-based access control policies either at the router or firewall prevents an attacker from crossing network boundaries to execute an attack.
Step 3: Use Multiple Firewall Interfaces with Source-Based Routing
Source-based routing policies look at the source IP address, and use a specific interface to transmit the traffic to the next device.
With modern, high-speed networks, information is transmitted at 1 gigabit per second (1 Gbps) or even 10 gigabits per second (10 Gbps), which is significantly faster than most internet links. In theory, the aggregate bandwidth between two devices can be increased by grouping multiple interfaces together, but in reality, unused (unneeded) interfaces can be used to split traffic based on a range of addresses because each interface can carry all of the traffic if needed. If an attack comes in from a certain range of addresses, it can be detected as increased traffic on a particular interface, making it less likely for an attacker to be able to overrun the whole device, and allowing administrators to quickly detect and stop an attack.
Source-based routing can be further used to split traffic in to multiple connections, between the firewall and app delivery tier.
Step 4: Use Multiple Server Pools
Using advanced virtualization techniques, capacity can be dynamically allocated between pools.
Rather than having two or three large pools, use the app delivery tier to further dissect the traffic in to, perhaps, twenty smaller pools, each of which have resources added dynamically based on load. If one pool becomes overloaded, the other pools are not affected.
Step 5: Design Application Architecture to Use Session Quarantining
Just as firewalls use connection quarantines to prevent SYN attacks, applications should shunt “young” sessions to a quarantine session pool, until they are proven.
DDoS attacks are not structured to perform complex transactions. Therefore, applications should be structured to quarantine sessions that have not been fully vetted. Once some “complexity” metric has been established, the connection can be moved from the smaller quarantine session pool to a trusted session pool. If the quarantine pool gets overrun, the server can start recycling connections without affecting the larger, trusted pool.
Conclusion
By splitting traffic in to as many paths as possible, and maintaining source-based access policies, an attacker is prevented from using globally-wide resources from overrunning a single connection.
Application connection pools should be configured to marginally trust “young” connections, and once vetted, transfer the connection to a trusted connection pool.
If an attacker overruns a single connection, or a quarantine connection or session pool, the rest of the network continues to function, unaffected.
Pingback: HOME | Justin A. Parr - Technologist
Pingback: Sony Playstation 4 – Long Term Review | Justin A. Parr - Technologist