In any major software development project, a broker tier is a critical element.
We’ll examine what a broker tier is, what it does, and several advantages to having one.
Table of Contents
What is a Broker Tier?
A broker sits between the application’s main code, and any other external components.
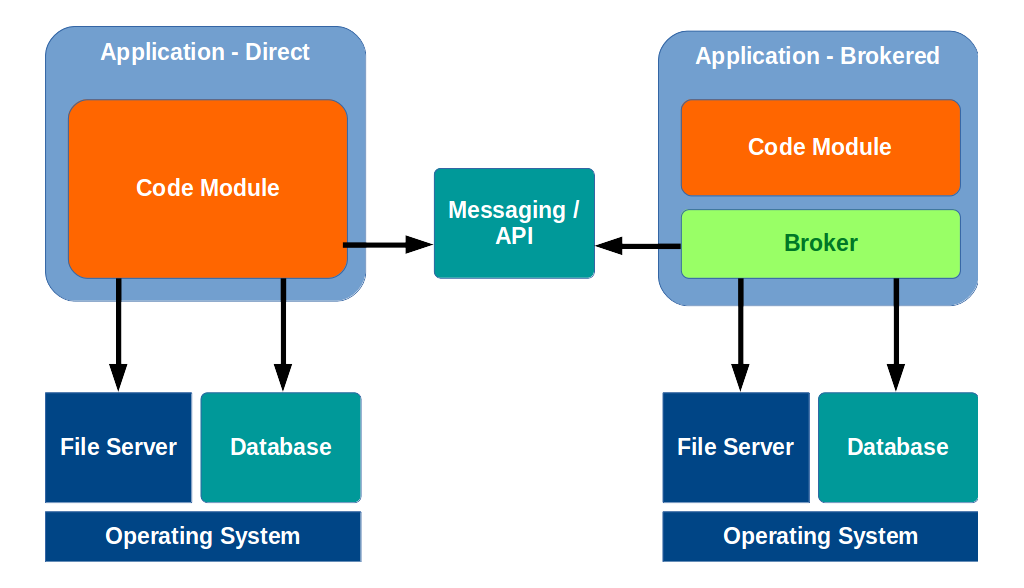
On the left, we see a typical application whose code module makes external calls directly.
On the right, we see an application that leverages a broker tier. The application’s code module makes a call to the broker, and the broker makes all external calls on behalf of the code module.
At first, this seems like needless overhead, but there are some very good reasons to include a broker tier in any non-trivial application.
Easily Support Different Technology Stacks
With a broker model, supporting any new technology stack requires few if any changes to the main code module.
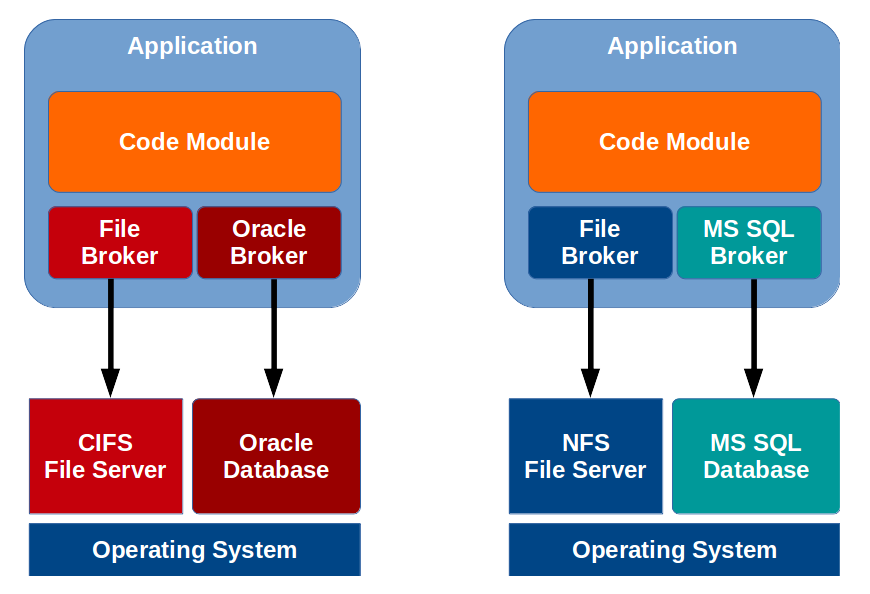
For example, if migrating from Oracle database to MS SQL database, then the database broker can be modified with MS SQL connection strings and query primitives, rather than having to search through the entire code base looking for database calls. Of course, triggers and stored procedures that encapsulate part of the application logic will need to be re-written, regardless.
Likewise, if migrating from a Windows-based CIFS file server to a Unix-compatible NFS file server, only the file broker must be updated to use Unix path notation and NFS calling convention, rather than Windows path notation and CIFS calling convention.
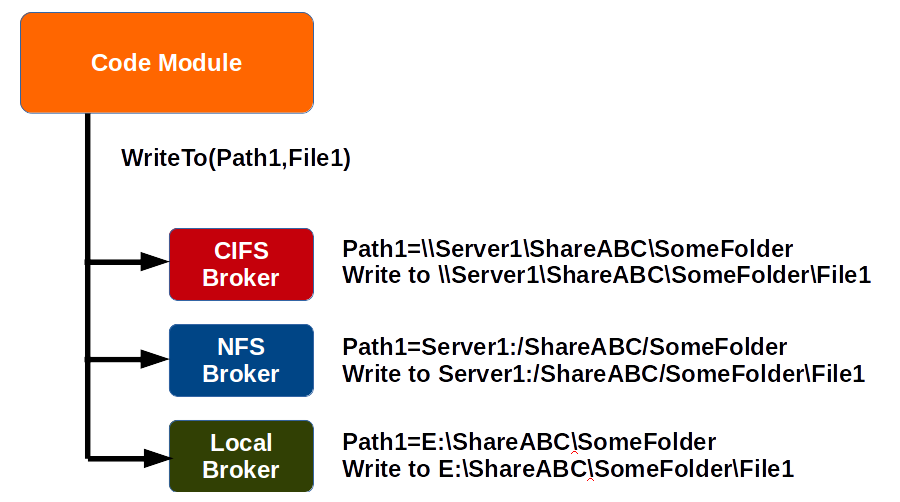
From the main code module’s perspective, the call to read or write a file can be generic, abstracted by a label that’s configured within the broker to point to a physical path. The main code module never needs to know the physical path, whether it’s local, remote, CIFS, Unix, or something completely different, such as database BLOBs or JSON object storage.
In the example above, “Path1” is a symbol that the main code module uses when it wants to write a file, and each of the three brokers can be configured to map “Path1” to a valid physical location based on each respective file system’s path naming conventions.
Meanwhile, the main code module doesn’t need to worry about the full path, and no code change would be required, should the path change, or if the underlying file server technology changes.
Using a broker simplifies configuration changes, and provides a modular approach to supporting multiple technology stacks, without having to modify the main application code.
Logging and Non-Repudiation
Any application should include robust logs that aid in troubleshooting, as well as non-repudiation.
Trying to incorporate logging in to an application often results in a dilemma around determining the correct atomic level of logging, as well as what elements to include in the log.
Having the broker perform the logging avoids needless verbosity, while ensuring that an entire transaction and all of its components end up in the log.
When coupled with time stamps, digital signatures, and other cryptographic artifacts, transaction-level logging can also provide the basis for non-repudiation – the concept that a particular transaction can’t be questioned, because there is evidence of every transaction.
Build in Redundancy / High Availability
Normally, when a critical component fails, such as a file server or database, the result is that the entire application crashes due to a cascade failure, and could even result in data loss.
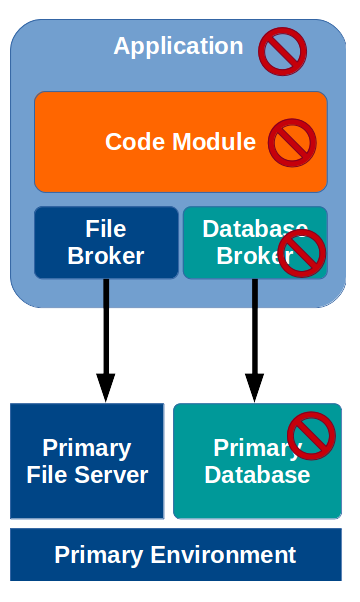
In the example above, the database fails, resulting in the database broker failing, resulting in a failure within the primary code module, which in turn causes the entire application to fail.
Typical high availability strategies rely on multiple copies of the data, or multiple instances, such that a failure of one component doesn’t result in a complete failure.
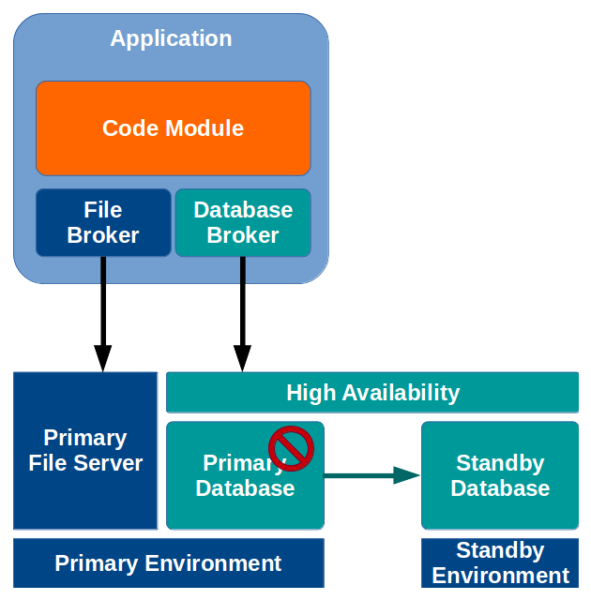
In the example above, information stored by the application in the database is replicated from the primary instance to the standby instance. Rather than communicate directly with one of the database instances directly, the application talks to a high-availability layer. If the primary database instance fails, the application is protected from failure by the high-availability layer, which automatically switches over to the standby database instance.
Although at first, this seems like a good way to handle redundancy and high-availability, there are a number of potential problems:
- Licensing for high availability often costs significantly more than a standalone instance
- Configuration is complex, and difficult to troubleshoot
- Sometimes, failover doesn’t occur automatically
- Slow replication can cause application performance issues, or could result in data loss
- Some high-availability strategies, such as clustering, don’t actually make a second copy of the data. Although the instance may be protected against crashing, the data itself isn’t protected against corruption or deletion.
Building fault tolerance in to the broker tier is a much better approach.
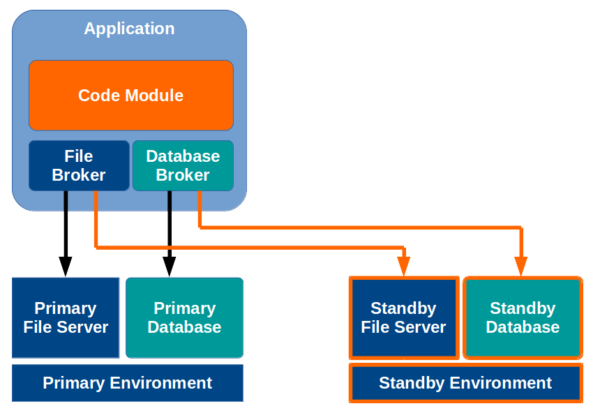
In the model above, the file broker and database broker each make an extra write in to a standby environment, to an extra copy of the file server and database (respectively).
In the event of the failure of a component in the primary environment, the broker itself can simply swing all of its read operations over to the standby.
The primary can be rebuilt as a copy of the standby, or missing transactions can be written to a queue on the standby, and applied later when the primary becomes available.
Using a broker for redundancy and high availability is a relatively simple and very reliable way to insure against unplanned down time and data loss.
Build In Application Performance Monitoring (APM)
For complex, distributed applications, a third-party APM tool sits between various layers of the application, gathering data, which is then crunched within the APM platform, yielding performance logging, alerting for sub-optimal performance, and realtime status (e.g. dashboard).
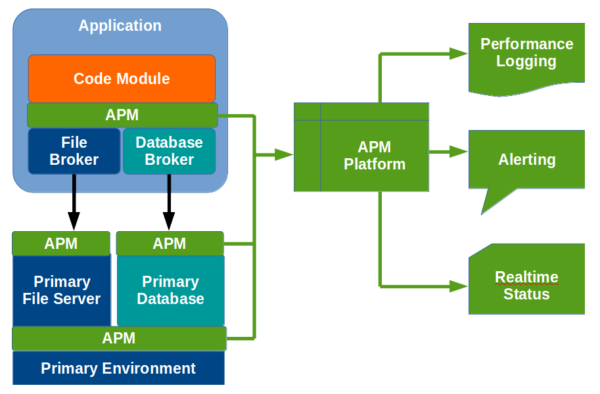
A decent APM platform can cost tens or hundreds of thousands of dollars, depending upon the extent of the features and deployment.
Conversely, by gathering a few statistics from the broker module, the application can perform its own APM.
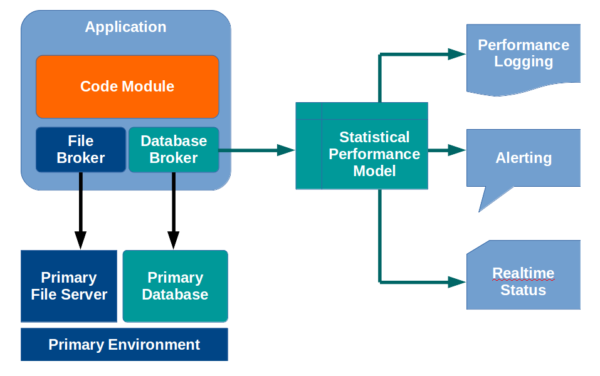
For example, by simply timing each query that passes through the database broker, the application can build a statistical model using any number of variables, to determine if any given query executed quickly or slowly.
These statistics can be stored in a performance log for review, or posted to a realtime display, such as a dashboard. Further, alerts can be automatically sent to application administrators in the event of application slowness.
Building Application Performance Monitoring (APM) in to the broker tier can save significant cost, and provide relevant business capabilities.
Conclusion
In addition to making your application lean and modular, broker architecture allows for sophisticated and powerful capabilities:
- Brokers are modular, which means that migrating to various technology stacks is just a matter of copying the existing broker code, creating a new module, and configuring the particulars of the new technology stack.
- Brokers provide an easy way to add logging and non-repudiation to any application.
- Brokers provide an easy way to add high-availability and redundancy for underlying technology stacks, rather than having to rely on expensive, complex, and perhaps unreliable component-level high-availability schemes.
- Brokers provide an easy way to add APM to any application, allowing for the native capability to perform statistical performance monitoring, in support of performance logging, alerting, and “dashboard”-style realtime status, without the need to acquire and implement expensive APM tools.
Every major application should be built with a broker architecture in mind.
Pingback: A Quick and Dirty Way to Get Rid of Insecure Protocols | Justin A. Parr - Technologist