The quote goes something like this:
Pi is an infinite, non-repeating decimal – meaning that every possible number combination exists somewhere in pi. Converted in to ASCII text, somewhere in that infinite string of digits is the name of every person you will ever love , the date, time, and manner of your death, and the answers to all the great questions of the universe.
Converted in to a bitmap, somewhere in that infinite string of digits is a pixel-perfect representation of the first thing you saw on this earth, the last thing you will see before your life leaves you, and all the moments, momentous and mundane, that will occur between these two points.
All information that has ever existed or will ever exist, the DNA of every being in the universe.
Everything: all contained in the ratio of a circumference and a diameter.
This is poetic, but false.
Read on, for my analysis…
Table of Contents
Introduction
I can’t find any attribution for the quote, but I see it pop up from time to time.
It’s a beautiful concept, but it just isn’t true, for many reasons.
Pi, denoted by the greek letter of the same name (“π”) is the constant of infinite length, which begins 3.14159, extends forever, and represents the ratio of the circumference of any circle to its diameter.
We’ve all seen this in grade school:
c = π * d
We can use this simple formula, leveraging this constant to calculate circumference or diameter for ANY circle given one or the other. Pi itself is simply the ratio of the two:
π = c / d
I will attempt to outline the major problems with the assertion that the digits of pi contain all the knowledge of the universe.
Logical Problems with the Assertion
Here are the assertions:
- The digits of pi are infinite in quantity
- The digits of pi do not contain any (non-trivial) repeating sequences
False Assertion #1: Pi must contain every number sequence
Assertions 1 and 2 together define the properties of ALL irrational numbers, not just pi.
Pi can’t contain itself, or else, by definition, it would repeat. For example, let’s say that pi appears within pi at position 52,672. That would mean that pi itself repeats every 52,671 digits. And, therefore we break assertion #2.
We can prove that pi can’t contain any other irrational number, either (except trivial subsets of itself, such as 1.4159…):
- If pi contains another irrational number (a completely different digit sequence), such as e (e is Euler’s Number, pronounced “oilerz number”, which is the base of the natural logarithm, also an irrational number), then essentially, pi is a finite sequence s that prepends e: pi = s || e (We use “||” to denote concatenation).
- We can then apply the same logic again to e, with respect to some other irrational number, such as √2. If pi contains e, and e contains √2, then both pi and e are finite (and therefore rational), while √2 is possibly irrational, where pi = s1 || s2 || √2, and e = s2 || √2.
- We can continue this logic for every combination of irrational numbers (again, except trivial subsets of themselves).
- This being the case, no irrational number can contain any other irrational number (except trivial subsets of themselves), or else itself is not irrational.
By extension of Cantor, we can prove that there is an infinite sequence of irrational numbers that CAN’T be contained within pi:
- For any nth digit of pi, d, apply a transformation function f(n,d) where d’ = f(n,d) such that d’ <> d.
- If this new sequence, pi’ appears anywhere within pi, then the first digit of pi’, d’1, would simply be re-transformed in to d”.
- There are an infinite number of transformation functions we can apply. For any digit value, there are 9 other digit values for d’ that do NOT match d. For any string of digits of length n, there are therefore 9^n possible digit strings that do NOT match pi. Further, we can include transformation functions that act on pairs of digits, triplets, or sequences of any length.
- Since there can be an infinite number of transformation functions, there are an infinite number of irrational numbers that do not appear within pi.
So clearly pi can’t contain itself or any other irrational number, other than obvious subsets of itself.
False Assertion #2: Every irrational number must contain every finite number sequence
Just because pi is both infinitely long, and never repeats, does not mean it’s compelled to contain all possible digit sequences.
For example, we can construct an irrational number procedurally:
- Define a function that returns a digit sequence, given a seed: f(s) = s repetitions of “1” followed by 0.
- Feed all positive integers sequentially in to the function, f, and concatenate the results
The result looks like this:
- 1 –> 10
- 2 –> 110
- 3 –> 1110
- 4 –> 11110
- etc…
The resulting digit string of f(1..infinity) would be:
x.10110111011110…
The digit sequence would be infinitely long (because there are an infinite number of positive integers), and would only contain repeats of the arbitrarily short sequence, “101”.
Note that pi itself contains duplicate, arbitrarily short sequences as well – there are only 1,000 possible 3-digit combinations, so therefore, you’re guaranteed to hit at least one duplicate 3-digit sequence by the time you compute 1,000 digits of pi.
Our procedurally-generated sequence above definitely does NOT include anyone’s name, time and manner of death, or any images (other than a triangle), but it absolutely IS infinitely long, AND non-repeating.
We can actually take this one step further.
For any given finite sequence of binary digits, b1, let r be the longest contiguous sequence of “1” digits within our finite sequence. We can exclude b1 from our procedurally-generated sequence by starting at f((r+1)..infinity).
For example, if the longest series of 1’s within b1 is 5 (r=5), then b1 would look like this:
…0111110…
By starting at r+1 (which is 6), the resulting sequence of f(6..infinity) will NEVER produce the sequence above.
x.111111011111110…
As a matter of fact, we can construct an infinite number of irrational sequences by adding any positive integer to r:
f((r+(1 .. infinity)) ..infinity)
For any arbitrary, finite, binary sequence b, there exists an infinite number of procedurally-generated, binary, irrational sequences s{} that exclude b.
Unprovable Assertion #3: Normal, irrational numbers must contain every finite number sequence
As far as we know, the digits of pi are relatively, evenly-distributed, meaning, the chance of a given digit being a 1 vs. a 2 vs. a 3 etc… is all approximately the same. This means that we think pi is a “normal” number. This basically means that “all probabilities are equal”, or, there is no weighting to the digits within pi.
Let’s attack this from the other direction. In general, we’ll cover encoding issues later, but let’s prove that pi might not include a specific ASCII-encoded string.
My name, in all upper-case, “JUSTIN“, in decimal ASCII is “074 085 083 084 073 078“. ASCII 074 = “J”, etc…
Following the assertion that an irrational, normal number must contain all strings, the above should appear at least once.
If we’re able to create a normal, infinite sequence that might not contain the above string (or any specified string), then assertion #3 might be false.
Hidden Rules
The most elementary attack is an assumption that there is some “hidden rule” of pi. For example, maybe there is a hidden rule of pi, that a 7 must appear 1 in 7 times. Here is our target sequence segmented by “7”:
- 07 –> Occurs 2nd
- 4085083084407 –> Occurs 13th
- 307 –> Occurs 3rd
- 8 –> (No occurrence of 7)
In our target sequence, segment #2 contains 13 digits, of which 7 appears 13th. If pi has some “hidden rule” that 7 must appear 1 in 7 times, our segment can’t appear anywhere within pi!
We don’t understand pi, so we don’t know if it has any “hidden rules” or not! Our example is rather short, but if we use a larger example, let’s say, the contents of the Library of Congress (an extremely long, yet definable and finite string), encoded as ASCII, any rule that says “a 2 must occur so often” would preclude accurately encoding such a long string within pi.
Another “hidden rule” might be that, perhaps, pi stops producing any digits other than 3, 5, and 8 after the 300 billionth position. We don’t know enough about pi to know if such a rule exists, or not.
We don’t know if pi has any “hidden rules”, but if it does, this precludes pi from containing any arbitrary, finite sequence which breaks one or more of the hidden rules, thus it’s uncertain whether pi contains all finite sequences.
Self-Similarity
The second type of attack is to construct a “normal-looking” number sequence that we know can’t include the string above.
The best approach is to use the properties of self-similarity, which is also the basis for fractal shapes and curves.
We can define a slightly more complex generation function f2(n) where n is the sequence number:
(I’m using “||” to denote concatenating two sequences)
- Let d be a statically-defined, infinite set of random digits
- if n<1, f2 = “” (empty string)
- If n>=1:
- Let sequence s1 = f2(n-1)
- Create sequence s2 as follows:
- Let l = length of s1 (count of the number of digits)
- For each position, i, in s1, let s2(i) = 9-(s1(l-i))
- f2 = s1 || d(n) || s2
Each step takes the previous sequence, adds one random digit from d{}, and then appends a transformation of the previous sequence, with each digit reversed in position and subtracted from 9 (modularly inverted).
This seems complicated at first, but let’s seed this with d={1,2,3,4,5}
- Since n=1, s1=”” and s2=””. The result is “1”
- S1 = f2(n-1), which is 1. We concatenate d(2) which is 2. We reverse the digits of s2, and subtract each from 9: 1 –> 8. The result is “128”
- S1=f2(2), which is “128”. We concatenate d(3) which is 3. We reverse the digits of s2 and subtract each from 9: “128” –> “178”. The result is “1283178”
- s1=f2(3), which is “1283178”. We concatenate d(4) which is 4. We reverse the digits of s2 and subtract each from 9: “1286178”. The result is “128317841286178”
- S1=f2(4), which is “128317841286178”. We concatenate d(5) which is 5. We reverse and subtract: “128317851286178”.
The result of f2(5) = 1283178412861785128317851286178
Assuming that d{} contains truly random numbers (not just 1,2,3,4,5), f2(infinity) would, through recursion, include all members of d{}, it would be infinitely long, and composed solely of random digits.
HOWEVER, due to the self-similar nature, it would NOT contain any information, except perhaps, trivially-short strings.
Taking just the first two letters of my name, “JU”, the resulting ASCII string is “074 085“. I ran ALL combinations of the sequence above, seeded with every combination of 6-digit numbers (including 0,7,4,0,8,5), and it NEVER produced the string “074 085”.
Although the sequence above is not as “normal looking” as pi – it has a lot of repetition, and digit distribution isn’t quite normal – it serves to illustrate the point.
Using the fractal-like principle of self-similarity, we’ve constructed a string using random numbers, guaranteed to not contain any useful information, other than trivially-short strings. There is no DNA sequence in there, and certainly not the entire contents of the Library of Congress.
We don’t know if pi follows the principle of self-similarity. However, just as the Mandelbrot Set doesn’t contain any pictures of a zebra, or a car, or my name, or my face, any self-similar sequence ONLY contains itself. If pi is self-similar, it only contains versions of itself.
Chaotic System
The third type of attack on this assertion is to look at pi as a chaotic system.
Chaotic systems don’t follow any rules! They are completely random, but they DO have boundaries and limits.
A chaotic system uses a simple calculation, iterated many times, where the output of the first is fed in to the next. Any “noise” in the system is quickly amplified until the whole system explodes in to chaos.
An ordered system, under the same iterated calculation, simply repeats itself, while a chaotic system produces non-repeating, random-looking sequences (sound familiar?)
To illustrate the difference, we know that a single pendulum is the epitome of an ordered system. For any given time, we can predict with a very high precision, the exact location of a single pendulum. We can even predict the next state of the pendulum based on its current state.
On the other hand, a double pendulum (also called a double-arm pendulum), is a chaotic system that quickly degrades from order to chaos, and calculating the position of either pendulum within the system becomes increasingly difficult for any given time other than t+1.
We can look at a chaotic system such as a double pendulum, and draw some analogies to pi.
There are many double pendulum, online simulators. I used the one from Clockwork Magpie Studios (thank you!)
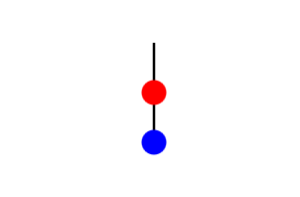
Here is a double pendulum at rest. The second pendulum in blue, hangs from the first pendulum in red. The blue pendulum pivots at the red point, and the red pendulum pivots at the top of its line. This simulator draws a blue line to trace the path of the bottom pendulum, which is perfect!
We’ll make both masses (m1 and m2) and pendulum lengths (l1 and l2) equal, set the starting angle to 90 degrees, and no friction. Here is our initial state:
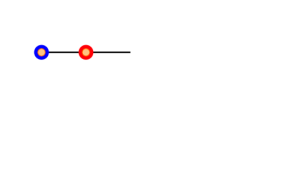
When we click “Run” to start the simulation,
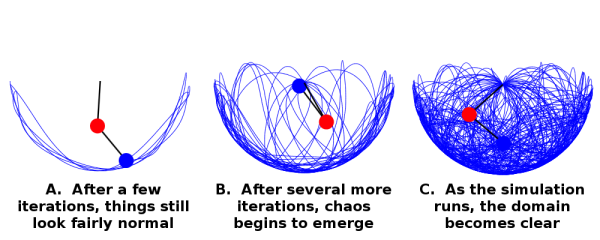
Starting off fairly normal, the blue line traces a path not unlike that of a normal pendulum. After several more iterations, things start to get chaotic, as the two pendulums frantically trade kinetic and potential energy. After quite a few iterations, the blue pendulum starts to fill in all the dots within the system’s domain.
The domain is bounded by the extent of pendulum 1 radius + pendulum 2 radius (r1 + r2), and the formula for a circle, but also by the amount of total energy. At the beginning, both pendulums were horizontal, so at any given time, the total amount of energy in the system can’t exceed its initial state, s, which was (m1 * g * h1) + (m2 * g * h2), or more simply, if h0 is equal to ( h1 at time 0 + h2 at time 0), then, for every state of the system, h0 >= h1 + h2.
The maximum height of either pendulum is limited to 1/2 the radius above horizontal (remember that r1 = r2). Because the pendulums are rigid, the math becomes a bit more complex, as the domain of the second pendulum at any point is limited by the domain of the first, but you end up with two half-teardrops on top of a half-circle.
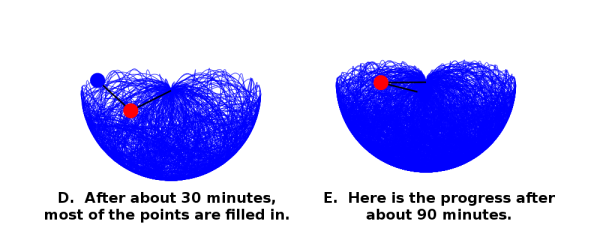
Note: After about 5 hours, it did not look significantly different than “E”.
Some readers might, at this point, proclaim “Aha! All of the points will eventually be filled in!”
The question is whether this system, an analogy for pi, can ever produce certain specific sequences of points.
Can it produce the letter “C”? Yes, it probably can.
Can it produce the letter “W”? NO, it can’t. The reason is that the entire system is always bounded by the amount of total energy at any given state, but also by the amount of kinetic vs. potential energy of either pendulum. Reversing directions for either pendulum requires kinetic to be converted to potential, or vice-versa. The only way to produce a sharp “v” or bend is to almost instantly transition between the two, in order to reverse directions. Under the right circumstances, you absolutely can produce a sharp “v”, but a “w” requires three such transitions in short order, otherwise, you might end up with the Greek lowercase letter omega (“ω”).
Although omega is a great letter, it’s not “w”, and we are asking the simple question: Is there any shape that this system CAN’T produce? Well, it can’t produce a “w”.
There is no way that this system can produce the letter “w” because it would require too many conversions between kinetic and potential energy, that have to happen almost instantaneously. This rules out triangles and squares as well, for the same reason.
In addition, what about a horizontal line that extends from one end of the domain to the other, through the shoulder of pendulum 1 (the red one)?
It can’t be done. As a matter of fact, the system can’t produce any horizontal line, spanning the domain, that falls between the shoulder and the lowest point of pendulum 1.
The reason is quite simple, the blue pendulum (2) would simply fall before the halfway mark, because most of its energy would be potential energy, or it would be pulled down by the red pendulum for the same reason. The two are exclusive, so there is no way for it to draw a line all the way across, where the blue pendulum sits above the red pendulum.
Drawing a horizontal line that completely traverses the domain of p1 would require more energy than exists in the total system. The red and blue pendulums would somehow have to levitate.
I can keep going, with other lines, shapes, and curves that ARE valid finite sets, but will simply NEVER appear in this system. Even if you let it run for infinity. Even if you scale it up to infinity, and let THAT system run for infinity (assuming you had a constant gravitational field, infinite in volume, in which to run it).
Let’s draw some analogies to pi.
Like our double pendulum, pi appears to be chaotic. If so, it’s most likely the output of some simple, iterated calculation with feedback loop.
Pi, like the double pendulum is bounded. Its domain is the digits 0..9.
Looking at any finite string within pi as simply “the state of pi at time t || the state of pi at time (t+1) || the state of pi at time (t+2)…” (remember: We are using || for concatenation), we see similarities to how the double pendulum draws a curve.
Any finite curve generated by the pendulum would simply be “the state of (p1 + p2) at time t || the state of (p1 + p2) at time t+1…” etc.
We know that there are certain sequences that just can’t happen within our double pendulum system, because they require resources that can’t exist within the system itself, such as a temporary burst of energy that can’t exist, or the ability to instantly change direction multiple times.
Likewise, even though we don’t understand it, if pi is truly chaotic, it’s just following a series of curves in “pi space” that we simply can’t see, but they are incapable of producing certain sequences.
Metaphysical Analysis
There’s nothing mystical about pi or any other irrational number. We just usually don’t express pi so that it’s finite. For example, pi can be expressed in base pi, which is 10! That’s simple, “10”.
Like many irrational numbers, pi is just a ratio: For a given circle, pi = circumference : diameter.
Like pi, there are other ratios that are irrational, such as the Golden Ratio: phi = 1+√5 : 2
Some ratios, such as 4:3, are also infinite in length, but rational, because they repeat: 1.3333333… etc…
When we express any of these as a decimal number, you basically get an infinitely-long error correction process. Rational numbers repeat or stop, because they CAN be adequately expressed with integer digits, while irrational numbers seem to never repeat because, like fractals, they CAN NOT be expressed with integer digits.
Conversely, because pi IS irrational, it’s not required to follow any set of rules! How do we know that after 200 trillion digits, the sequence of pi digits only contains 1’s and 0’s? Or 5’s, 3’s, and 8’s? There are no rules, and no guarantees.
However, even with a “normal-looking” distribution of digits, we’ve demonstrated that an irrational number can fail to contain any information. Pi could simply consist of the metaphorical equivalent of television static.
Just as the noise of waves crashing against a seashore is random, and no two waves are exactly identical, even if we listened to it for infinity, it would never exactly repeat, but we would never hear the waves whisper our spouse’s name, nor crank out the entire tune to Beethoven’s 9th symphony… the “noise” produced by waves are simply not structured to be able to do this, nor are the digits of pi (so far as we know) structured to be able to produce any useful information.
Encoding and Information
What is ASCII?
The meme specifically calls for information to be encoded in “ASCII text”.
ASCII is the 7-bit American Standard Code for Information Interchange, invented by Bell labs in the early 1960’s. Even though it is an American standard, it was THE world-wide standard for encoding data in to 7 and 8-bit binary, from 1963, when it was published as a standard, until it was surpassed by ANSI Unicode (a modern, 16-bit, international standard) in the late 90’s.
The reason we need ASCII is that computers store information in binary, using 1’s and 0’s. ASCII allows higher-level symbols to be encoded in binary using 8 bits (or 1 byte) per symbol. So the letter “A” is ASCII value 65, but the computer sees it as 0100,0001.
In the 1970’s and 80’s, all microcomputer systems used either 7-bit ASCII, or an 8-bit symbol set that included ASCII as its first 128 values. In 1981, IBM released the IBM PC, the precursor to all Intel / AMD / Windows / x86 / x64 systems, with yet another 8-bit encoding scheme that included 7-bit ASCII. Known as the PC symbol set, it was eventually superseded by the Unicode UTF-8 symbol set, which is a 16-bit code table that includes the PC symbol set as its first 256 values, which in turn includes ASCII as its first 128 values.
So, even today, ASCII encoding is embedded in every computing device, and allows computers to share information without losing the meaning of the information. The capital letter “A” is ASCII code 65 (decimal), and the specific binary encoding of 65 represents the capital letter “A” on every computing device. Thus, you can write an essay on an Android tablet, and your letters, capitalization, and punctuation will remain in tact when viewed on virtually any other computing system.
ASCII is also the reason why you can create a password on your PC that unlocks your iPad and Android tablets. If it were not for ASCII, every password would be device-specific!
Here are some interesting ASCII facts:
- The first 32 characters, 0 through 31, are known as control codes, and were designed to tell early terminals how to format incoming text as it’s displayed.
- ASCII 7 is the “BELL” symbol, used on 7-bit teletypes to ring a physical bell, usually indicating an incoming transmission. To this day, printing ASCII 7 will cause most computer systems to produce a “beep”.
- Backspace is ASCII 8, and TAB is ASCII 9.
- The infamous Carriage Return (CR) and Line Feed (LF) sequence are ASCII 10 and 13. DOS / Windows uses CR+LF to advance to the next line of text, while Unix-based systems tend to use only LF.
- ASCII 32 decimal (20 hex) is the “space” character. This is bit 6 within an 8-bit encoding scheme: 0010,0000
- The digit “0” is located at ASCII 48 (hex 30), with all subsequent digits encoded sequentially through ASCII 57 (“9”). To encode a digit in ASCII, simply add 48.
- Capital “A” starts at ASCII 65 (hex 41), followed by “B” at 66, etc..
- Lower case “a” starts at ASCII 97 (hex 61), followed by “b” at 98, etc…
- If you take any text, and enable bit 6 (bit-or 32), you convert from upper to lower case. Likewise, if you disable bit 6 (bit-and 223, which is 255-32), you convert from lower to upper case. For example, 65 “A” + 32 = 97 “a”, while 97 – 32 = 65.
- EBCDIC, a competing standard from IBM, was an early 8-bit attempt to include internationalization. Letters, numbers, and symbols are all intermixed, and appear in different locations than their ASCII equivalents. EBCDIC text, when viewed on an ASCII or UTF-8 system, will appear as garbage.
Virtually every computer system, except IBM mainframes, use ASCII or UTF-8 encoding.
Encoding
Pi consists of the digits 0 through 9.
This presents some logistical problems when used to encode already-ASCII-encoded information, because ASCII is a binary-based encoding scheme.
When encoding ASCII as a decimal (base 10) number, each symbol (letter, space, number, punctuation) requires 3 decimal digits:
- 032 = space
- 048..057 = 0..9
- 065..90 = “A”..”Z” (Upper-case)
- 097..124 = “a”..”z” (lower-case)
The meme specifically calls out ASCII encoding. At minimum, you need 3 digits due to lower-case letters, but let’s say that you don’t need lower-case letters — we can then encode each ASCII symbol using two decimal digits:
- 32 = Space
- 48..57 = 0..9
- 65..90 = “A”..”Z”
Using this encoding scheme, my name, “JUSTIN”, is: 748,583,847,378
Both of these sequences contain the same information, encoded in ASCII, which are subsequently encoded in to pi using two different encoding schemes:
- 2-digit encoding: 748,583,847,378
- 3-digit encoding: 074,085,083,084,073,078
We can even develop some new encoding scheme that maps back to ASCII.
2-digit encoding is still horribly inefficient, because each pair can encode up to 100 symbols (“00” through “99”), yet we only need a few symbols to meaningfully represent information:
- 10 digits (0-9)
- Space (10)
- A..Z (11-36)
This reduced symbol set results in space (1) + digits (10) + letters (26) = 37 symbols.
This means that any string of symbols can be encoded in base 37. The string, “abc” would be encoded like this:
- A = 11
- B = 12
- C = 13
- The string is length 3, so we will use positions 37^2 for the first position, then 37^1, then 37^0
- 11 * 37^2 + 12 * 37 + 13
The resulting sequence is: 15,516
So, with an efficient coding scheme, excluding compression and de-duplication algorithms, here is the breakdown:
- A single symbol requires two decimal digits (0..36)
- 2 symbols require 4 decimal digits (0..1,369)
- 3 –> 5 digits (0..50,653)
- 4 –> 7 digits (0..1,874,161)
- etc…
- 7 –> 11 digits (0..94,931,877,132)
This sequence converges at 37^7 which is about equal to 10^11, meaning that every 7 symbols can be efficiently encoded within 11 digits of pi, or each digit contains 0.64 of one ASCII symbol.
My name, encoded using this scheme, would be:
JUSTIN –> 20,31,29,30,19,24
In base 10: 1,446,488,865
We have yet another encoding method that yields a different digit sequence, and there are an infinite number of encoding methods we could use.
If pi is speaking to us, maybe we don’t know how to decode the information! Moreover, why would pi choose ASCII, which is relatively inefficient?
Information Content and the Effects of Encoding
When we look for information contained within a digit sequence, the first thing we have to do is figure out the digit sequence for which to look. We do this by taking the raw information, and encoding it.
Information is a specific arrangement of matter and / or energy. When we encode information using any particular scheme, we’re really transcoding it – we observe some chunks of matter (such as words, printed on a page), or we take some specific measurement of energy (such as a radio signal), and we’ve all agreed on what those observations and measurements represent, based on the rules of language, syntax, grammar, and alphabet. We then take this information and use a new set of rules in order to create a format that fits the digits of pi.
As we’ve seen, there are three rules to our encoding scheme:
- Pi only contains the digits 0..9. We can’t use any other symbols, so our encoding scheme must not break this rule.
- The meme calls out ASCII encoding, but that leaves some interpretation that we’ve explored, as well as plenty of room for optimization.
- The distribution of resulting digits must be “normal”, meaning, all digits must have an equal (or nearly equal) probability of occurring evenly, because we think the digits of pi are “normal”.
We’ve also seen that there are many different possible encoding schemes, but by the meme’s definition, we should be able to use 3 digits per symbol to encode any arbitrary string, and find that sequence within pi.
In ASCII, my name, “JUSTIN“, in decimal ASCII is “074 085 083 084 073 078“. We need 3 digits because the specification for ASCII is 7-bit, capable of encoding any value from 0 to 2^7-1 = 127. 127 > 99, therefore, you need 3 decimal digits to encode any arbitrary ASCII symbol.
So let’s look at the digit distribution for {Space, {0…9}, {A..Z}..{a..z}}, excluding punctuation, which would be the minimum symbol set required in order to encode “a name”, “a time”, “a manner”, etc…
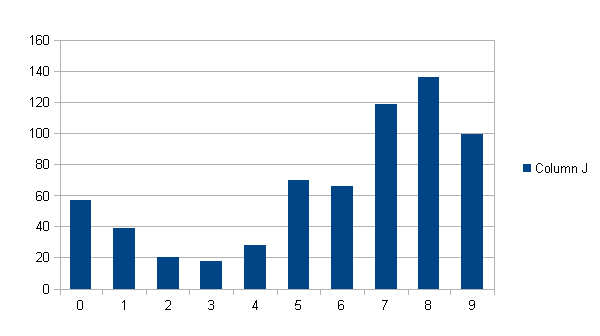
Any information encoded in ASCII would need these symbols, yet the digit probability of information appearing within pi precludes the so-called “normal” distribution of the digits of pi!
If 3 appears with equal frequency to 8, then pi will have to perform an extraordinary reach, in order to encode anything useful, encoded in 3-digit ASCII!
Let’s eliminate all lower-case letters, which allows us to encode 1 symbol using two decimal digits.
My name encoded in 2-digit ASCII is: 748,583,847,378
This certainly looks more normal, but here is the digit distribution:
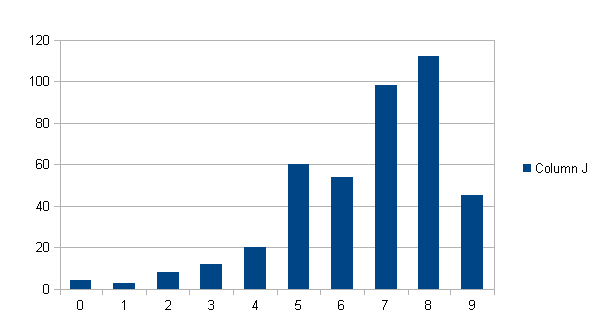
What appeared at first to be a fighting chance, results in worse odds! Information encoded using 2-digit ASCII is even LESS likely to occur within the digits of pi!
What about our super-efficient encoding scheme?
Our largest number is 94,931,877,132 which is 37^7
The digit distribution will vary by 10^10 or more!
Because information is the SPECIFIC ARRANGEMENT of matter or energy, it necessitates an encoding scheme that defies entropy: The force that silently lurks behind the scenes, working toward making everything equally-distributed.
Any encoded form of information is a specific arrangement that defies entropy, and is therefore not equally-distributed. Thus a “normal” number is not likely to contain useful information.
We are using a subset of the ASCII table, which means that our information is already encoded. The distribution of symbols within the ASCII symbol set follows a specified distribution (Zipf’s Law), but when we take any specific piece of information and then re-encode it within pi, the resulting digit distribution within pi simply can’t be “normal”.
Likewise, scientists in New Mexico continuously look for a ratio of signal to noise, called the “SNR”, or “Signal to Noise Ratio”, or the ratio of the number of “1” bits to the number of “0” bits, in order to try to look for alien communications. If either the “1” bits exceed the “0” bits by a far amount, or vice-versa, then there is a high likelihood of there being information contained in the string.
This reinforces the concept. When the digit distribution of a given sequence is equal, you get random static. When the digit distribution is asymmetric, you have a higher probability of the sequence actually containing information.
The reason they look for an asymmetric distribution is because information theory requires that any message containing meaningful information must be encoded using an asymmetric distribution of symbols.
The Oracle Paradox, or The Nostradamus Effect
Here is something we might find, predicted in pi:
A powerful man turns to darkness and seeks to rule all
Father and son are in conflict
He casts his son’s hand aside, yet offers an alliance
Son eventually defeats father, and returns him to light
Is this a biblical prophesy? No, I was actually referring to Darth Vader. In order to properly understand and act on this “pi-rophecy”, you must know who Darth Vader is, and you must be familiar with the plot of three movies in the “Star Wars” series. Further, you must have some context to know that this refers to a movie, a fiction, versus some real-world dictator.
The Nostradamus Effect refers to the 13rh-century prophet, Nostradamus, who predicted all sorts of stuff.
His predictions were vague, and therefore, subject to interpretation, and ONLY AFTER some event occurs, the so-called prediction comes true. Meaning, looking backwards, any arbitrary prediction can be matched with known events. As time progresses, the chances of some arbitrary prediction “coming true” is more likely.
I’ll generalize this, and call it the “Oracle Paradox”
Oracle Paradox:
You don’t know which answer goes with which question, unless you already have an answer to a given question!
Take the Mattel “Magic 8 ball” as an example. This “oracle” provides one of 20 answers at random, and you are expected to state your question aloud, shake the 8-ball, then view the answer.
Well….
This leaves quite a bit to be desired, when you have the expectation that the “8 ball” is an accurate oracle.
First of all, you can ask the same question multiple times, and get different answers.
“Will I find TRUE LOVE?” You shake the 8-ball, and…
…
(I’m building suspense…)
…
“Ask again.”
Eh. :-/
OK, let’s ask again…
The probability of this oracle answering “YES, DEFINITELY” is the same as “NO, ABSOLUTELY NOT”, yet, the odds reflect that the most LIKELY outcome is something ambiguous.
I can ask 1,000 times, the probability of a clear answer is 2/20, therefore, in only 1/10 cases will I get a “YES” or a “NO”, and both are equally likely.
If I ask the 8-ball oracle, “DID I find true love?”, I can simply discard all the wrong answers, because I already know the right one!
Let’s apply this same logic to pi.
We are going to create an uberduber program called: “The Oracle Of Pi”. And you better tremble with fear when you say it, and there had better be an echo! Because this program does the most incredible thing that ANY program could POSSIBLY do.
The Oracle of Pi searches through the INFINITE digits of pi, and within seconds, it returns an answer to any question.
So here is the problem: HOW THE HECK does it interpret the question and translate that in to an answer??? In reality, the Oracle of Pi is nothing more than a magic 8-ball, spitting out random strings when confronted with a particular question. It must rely on encoding rules, and English language rules, in order to find strings within pi, but there is no way to contextually answer any question using these arbitrary strings.
So I can ask the question: WHO is my TRUE LOVE? The Oracle responds, “Ask again later” :-/
I ask again. The oracle responds with the first string it finds, “SAMANTHA!” That’s awesome! I’m going to exclude all other possibilities, and go look for some bride-material named “Samantha”.
I ask the same question again, and this time the Oracle spits out “Melody”. Uh… Is my true love Samantha, or Melody?
That’s the problem. We CAN’T know that in advance.
After I DO find and marry my true love, I can ask the Oracle one last time, who then delivers the correct answer, because it doesn’t have to interpret anything, it just searches for the string I’ve already given it.
Due to the Oracle paradox, we can ONLY look backward, in order to find any significant information in pi.
I’ll illustrate a special case: One of Superman’s arch-villains is Mxyzptlk. Even my spell checker is blowing up on this one. Mxyzptlk is a 5th dimensional trickster who dogs Superman until he tricks the trickster in to saying his name backwards.
So Superman, in a last-ditch effort, asks the Oracle of Pi (YOU WHO ARE READING THIS, You had better tremble, and imagine a HEAVENLY ECHO when you say the name of the Oracle of Pi, for, it is ALL KNOWING, ALL SEEING!)
And Superman asks: “How can I get rid of Mxyzptlk?”
The all-powerful oracle either crashes or runs forever.
Superman then asks Oracle of Wikipedia (a far more durable and useful oracle), who in mere tenths of a second responds, “You must TRICK Mxyzptlk in to saying his name backwards.”
You would think that the Pi Oracle, with VAST AND INFINITE access to information, would realize this!
BUT, the answer doesn’t APPEAR to contain any information, because the word, “Mxyzptlk” doesn’t contain any vowels! Thus, the Pi Oracle ignores it. Kltpzyxm is OBVIOUSLY not a real answer because it doesn’t conform to the rules of English!
Likewise, we won’t get any answers that include the word “Egypt” nor any specific word that doesn’t have a “normal looking” vowel distribution.
Inquisitor: WHO built the great pyramids?
Oracle: ….
Inquisitor: You are all powerful, with all the knowledge of the Universe! HOW CAN YOU NOT ANSWER!?
Oracle: (%15 – Installing updates. Do not power off or unplug your Oracle until updates are complete.)
:-/ Well…. CRAP!
Due to the oracle paradox, even if pi DID contain useful information, it would spit out random answers that we would then have to somehow match to a question, thus precluding the usefulness of the (reverb and tremble) Oracle of Pi.
Deterministic Sequence
Now that I’ve completely destroyed the metaphysical aspects of pi, let me demonstrate two math thingies that DO contain the universe, or at least significant parts of it.
Champernowne Constant
A Champernowne Constant for a given base is a systematic enumeration of all combinations of the symbols of the given base.
For example, the Champernowne Constant in base 2 is the following, concatenated:
- 0, 1 (all 1-digit series)
- 00, 01, 10, 11 (all 2-digit series)
- 000, 001, 010, 011, 100, 101, 110, 111 (all 3 digit series)
- Etc…
The result: 0.100011011000001010011100101110111…
Looking at our binary example far above, we said that we could construct a series that EXCLUDES an arbitrary string based on the number of consecutive “1” symbols.
Conversely, the Champernowne Constant for base 2 is REQUIRED to contain all finite strings.
For any given string of n digits, We would simply “fast forward” to the portion of the constant where n-series strings are stored. The target string is somewhere between this position, p, and p + (2^n)-1
Likewise, we can construct the base 10 Champernowne:
- 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 (all 1-digit series)
- 00, 01, 02, 03… 98, 99 (all 2-digit series)
- 000, 001, 002… 998, 999 (all 3-digit series)
- Etc…
The result: 0.1234567891011121314151617181920212223…
This sequence, “converted to ASCII”, absolutely DOES contain my name, the name of my wife, the entire contents of the Library of Congress, and every DNA sequence of every living being who ever lived, or will ever live.
It DOES NOT contain any irrational numbers, so even this all-knowing constant has the same limitation. If it contains pi, it can’t contain e. If it contains pi or e, it can’t contain √2. If the constant were to include an irrational, it would be “locked in” to the digits of that particular irrational, which is infinitely long. The two would coincide for the remainder of both, except for some fixed-length preamble that preceded the irrational.
The constant absolutely DOES contain an APPROXIMATION of pi, and e, and √2, and all irrationals, when approximated to any FINITE number of digits. For example, 3.14 (a 3-digit approximation of pi), is guaranteed to appear within the first 3,209 digits of Champernowne, because the first 3,209 digits of Champernowne contains ALL 3-digit sequences. Precisely, it appears at position 1,152.
The other nice thing, is that we don’t have to worry about an encoding scheme! EVERY encoding scheme for EVERY finite ASCII string is in there! We can use 2 digits or 3 digits, or heck, even 10 digits per character, and EVERY representation is in there.
Going back to our highly-optimized example, my name, “JUSTIN” is 1,446,488,865 in base 37, and is GUARANTEED to be in the sequence at position 24,341,431,860.
We can also go with some exotic encoding scheme, where we find our answers using only the odd digits of Champernowne. It still works the same way.
There is only one obvious weakness: Due to the oracle paradox, you must know the answer to any given question, before you can find that answer within the digits of Champernowne’s constant.
Even worse, we have to be REALLY careful, because we know it DOES contain approximations of other numbers. Suppose we ask it, “What is the 3rd digit of pi”? Well, we know that the right answer is “1”: 3.141(59265…), but that sequence DOES exist alongside 9 wrong answers, starting with 3.140 through 3.149.
Suppose we feed it 50 digits of pi and ask for the 51st. We still have only a 1 in 10 chance of finding the correct answer, unless we know in advance what that 51st digit should be.
So the good news is that “all the answers are in there”, and the bad news is, “…even the wrong ones”.
Tupper’s Self-Referential Formula
Tupper’s self-referential formula is a formula that can be used to draw a picture of itself.
This formula (lifted from wikipedia):
![]()
Produces this picture:

When you feed it this constant:
960 939 379 918 958 884 971 672 962 127 852 754 715 004 339 660 129 306 651 505 519 271 702 802 395 266 424 689 642 842 174 350 718 121 267 153 782 770 623 355 993 237 280 874 144 307 891 325 963 941 337 723 487 857 735 749 823 926 629 715 517 173 716 995 165 232 890 538 221 612 403 238 855 866 184 013 235 585 136 048 828 693 337 902 491 454 229 288 667 081 096 184 496 091 705 183 454 067 827 731 551 705 405 381 627 380 967 602 565 625 016 981 482 083 418 783 163 849 115 590 225 610 003 652 351 370 343 874 461 848 378 737 238 198 224 849 863 465 033 159 410 054 974 700 593 138 339 226 497 249 461 751 545 728 366 702 369 745 461 014 655 997 933 798 537 483 143 786 841 806 593 422 227 898 388 722 980 000 748 404 719
That’s amazing!
But, it’s really just a decimal encoding scheme for any arbitrary binary 17 x 107 bitmap.
You could create any picture you want, encode it in binary, and then encode it in to decimal using the proper encoding rules.
I lied when I said it contains everything. It actually only contains anything you can draw in two colors within a 17 x 107 grid, thus it contains a finite amount of information: 2^ ( 17 x 107 ) bits.
STILL VERY COOL, but not infinite, and still has the same limitations as every other oracle: We can’t find the answer unless we know it ahead of time. If I knew the last image I’d see before my death, I could use Tupper to draw it, which is pretty cool, but I can guess that a blocky, squashed image is going to have limited usefulness.
Conclusion
- Pi can’t contain any other non-trivial irrational number
- There are other irrational numbers that exclude a specific finite sequence
- We don’t know if pi contains all finite sequences, but it probably doesn’t!
- Pi might be chaotic or self-similar, or might have a hidden rule that precludes it from including specific finite strings. We don’t know!
- The meme calls out ASCII encoding, which is actually, horribly-inefficient
- Regardless of the encoding scheme, pi seems to have a normal digit distribution, which precludes that pi actually contains any useful information.
- The Oracle Paradox requires that you know the answer to a given question, prior to asking the oracle. In other words, we can only find the answers in pi (or any system) whose values are already identified. We can never ask an open-ended question, because we don’t know which answer goes with which question.
- There actually ARE mathematical systems that DO include all finite strings, and….. none of them are pi.
Myth…. BUSTED.
(Waiter? Check, please)
Pingback: Is Pi A Number? – Fallsgardencafe
Pingback: Test of different streaming services – Stream Of Random Podcast
Pingback: STREs3e416 Complex Systems – Stream Of Random Podcast
Very interesting. Pi is always a good topic. Prime numbers is another one.
Just one quick note – my friend pointed out that Pi contains itself. Once in a trivial manner – 3.14… 3.14 ….
So section 2.1, second line should be corrected or clarified. Same like with prime numbers, where 1 is excluded. Pi cannot contain itself but besides a trivial case.
Pingback: Chaos, Deterministic Randomness – Science Scholars 2018
Pi contains every possible 4 digit luggage lock combination. And 5 digit, 6 digit, and so on. For the myth to be false… there must be some length of a combination where you can’t find every possible sequence in pi and only a subset can be generated (similar to your chaotic system analogy). But no one has found that length, though that doesn’t preclude it from existing. I suspect most mathematicians would say it’s too soon to declare whether pi contains all finite sequences or not, or to even put a probably on one side or the other of the outcome.
At the same time, if pi does contain every possible finite sequence, it’s trivial in the sense that any infinitely long random and independent sequence will have that property. It’s only speaking about randomness and infinite processes rather than any magic in pi.
100% Agree.