How to guestimate peak volume, and volume at any arbitrary time using total volume with an elliptical distribution curve.
Someone says, “we have 10,000 hits per day on our website”, but what does that mean from an instantaneous demand standpoint?
A distribution curve can help you figure that out.
Table of Contents
Simple Formula for Guestimating Peak Sessions for a Given Volume of Traffic
I’ll give you the goods up front.
p = ( 4 * V ) / ( pi * t )
- P is the peak volume per hour, for which we’re trying to solve
- V is the total volume for the time period
- t is the number of hours in the time period
- Pi is the constant 3.14 (etc…)
Simple example:
If you’re building a website that will run a business application, and you’re expecting 20,000 sessions per day, randomly distributed throughout the day, between 8 AM and 5 PM, then we can calculate the peak as follows:
T is the time in hours, or 5 PM – 8 AM + 1 hour (10)
p = ( 4 * 20,000 ) / ( 3.1416 * 10 )
p = 80,000 / 31.416
p = 2,547 hits during the peak hour
Or, between 42 and 43 sessions per minute.
If you want more information on how or why this works, read on…
Distribution Curve
A distribution curve is a way to generate, or guess, the points of a histogram based on certain known values – for example, knowing the total number of data points allows a distribution curve to plot how those data points are distributed among multiple slices or buckets, according to a formula.
Histogram
“Slow down! What in the world is a histogram???”
Fair enough!
A histogram counts the number of data points that fall within each slice of a specific range of values.
For example, if you go to the grocery store, there might be 10 checkout lanes. If you plot the lane number across the bottom (X-axis) of a graph, and then count the number of people in each lane, plotting that number as the Y coordinate corresponding to that lane’s X coordinate, you have a histogram!
In this example, you have 10 lanes (or buckets), and you’ve counted the number of people in each lane.
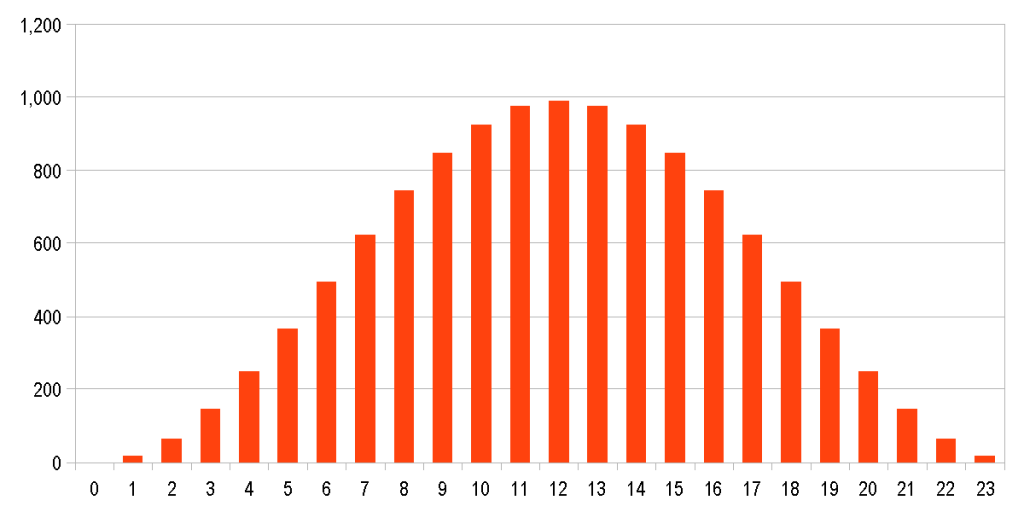
When performing capacity planning, histograms are often used to count the number of hits for each hour of the day – e.g. the buckets are 0 (12:00 AM) to 23 (11:00 PM), and a hit gets counted in to one of the 24 buckets based on the time of day in which the “hit” (request) is submitted to the server.
This type of graph helps answer the questions:
- What time of day is my system being used most often?
- When can I safely perform system maintenance, disrupting the fewest customers?
- What is my peak resource demand (utilization)?
Creating a usage histogram requires detailed log analysis, and there are plenty of commercial and open source analysis tools that can create one.
The problem with this approach is that you need usage data to create the histogram! What if you’re building a new service, and there is no data available?
A distribution curve can help you project what the histogram will look like.
Distribution Patterns
There are various types of distribution patterns.
Bell Curve
Statisticians discuss a bell-shaped distribution curve. This curve appears when analyzing how data points relate to the average of all data points within the set.
This sounds really complicated, but let’s walk through it…
Let’s say that you ask 100 people their age. Let’s say that the minimum age is 10, and the maximum age is 80. Statistically, the average is going to be about 35. If you plot a histogram based on the distance (or difference) between each data point (person’s age) and 35, most data points will cluster at the 0 mark (right at 35) and will drop off in an inverse curve to the left and right of 0 (the data point labeled “35”). At the outer edges, there will be a few data points in the low age range to the left, and a few data point in the high age range to the right.
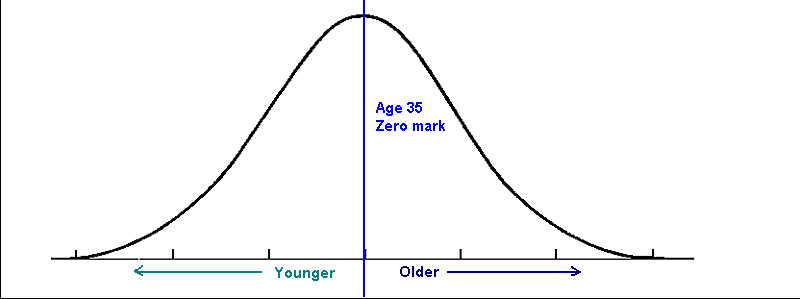
This shape is known as the bell-shaped curve, where 90% of all data points fall within the center 50% of the entire range of data values.
This is also the basis of the famous 80/20 rule, where 80% of data points within the center 20% of the range of data values, while the remaining 20% consume the remaining 80% of the range.
Linear Distribution
A linear distribution is literally a “line”.
The formula for a line is:
y=m * x + b
- X is the independent variable
- M is the slope of the line (y/x)
- B is the Y intercept – the value of Y, where x=0.
Linear distributions could be flat, meaning every Y value is the same. What this means in the real world is that every time bucket has the same number of hits, or that traffic is constant around the clock. This never happens. Every application has peak and off-peak utilization.
Linear distributions could be a fixed slope, meaning that traffic progressively increases or decreases at a constant rate (or maybe a combination of the two) until the cycle resets at a specific clock time. Again, this never happens.
Linear distribution is easy to calculate, but not very useful.
Cosine Curve
A cosine curve is based on the cosine formula for a right-triangle:
COS = Opposite / Hypotenuse
To find the height for a given x coordinate, you must supply an angle.
In degrees, the angle is specified in a range of 0 (north) through 180 (south) to 360 (or back to 0).
In radians, the angle is specified in a range of 0 (north) through pi (south) to 2 * pi (or back to 0).
By pinning the angle to the x coordinate, you can generate a curve.
Using the time buckets example, if we map 360 degrees to 24 time buckets, that’s 15 degrees per hour.
Given some peak magnitude, p, the height of the curve at a specific time t is:
y = COS (t * 15) * p
This produces a familiar shape…
In fact, the bell curve can be approximated using a cosine curve.
Most real-world usage patterns can be approximated using a cosine curve.
Elliptical Distribution
An ellipse is a stretched-out circle.
Using half of an ellipse, you can generate a very good approximation of real-world usage, using the much simpler formulas that describe a circle.
Generating an Elliptical Distribution
Given a total daily volume of server hits, V, we can quickly approximate the peak volume, p, as well as the volume y, at any given time, t.
Calculate Peak Volume
The area of a circle is described by the following formula:
A = pi * r^2
- R is the radius of the circle.
- PI is the constant, pi (3.14 etc…)
An ellipse is a distorted circle, where the vertical and horizontal radii are different:
A = pi * a * b
- A is the vertical radius
- B is the horizontal radius
Let’s map some variables to our formula:
- V, our total volume, is really 1/2 the area of the ellipse, or A/2. We don’t want our distribution to include the part of the ellipse that falls below the zero line.
- T is our timeline, the number of time buckets where we expect the utilization to occur, which would be the entire horizontal diameter. We only care about 1/2 the timeline, or t/2 as the horizontal radius B
- A is the vertical radius, which is actually the peak volume, p, which is what we’re trying to find.
Putting it all together:
V = A/2
A = pi * p * t/2
therefore,
V = (pi * p * t/2) /2
V = pi * p * t /4
Solving for p:
p * pi * t = 4 * V
p = (4 * V) / (pi * t)
Defining the Timeline
The timeline is the series of time buckets included in the analysis.
The ellipse will return a 0 value at the beginning, where it crosses the x axis (x intercept), and a second 0 value at the end, which is the second x intercept.
This means that you need to include the time bucket immediately preceding the first period of utilization, as well as the time bucket immediately following the last period of utilization.
Let’s say for example that the application in question will be primarily used from 8 AM to 8 PM. What this really means is that there will already be some utilization right at 8 AM, so the 8 AM time bucket can’t be 0. The timeline has to start at 7 AM (the first x intercept).
At the end of the day, we’re saying that NO ONE is on the system AFTER 8 PM, reflecting that the last period for utilization is 7:00 PM through 7:59 PM – all of this sits in the 7:00 PM bucket. The 8 PM bucket should be empty, which is our second x intercept.
We want to count the buckets FROM one intercept TO the other. We have 12 time buckets with actual data (8 AM –> 7 pM ), and we need to include one more to account for the fact that there is not zero traffic at 8 AM.
So in this example, if we say we’re interested in traffic from 8 AM to 8 PM, we need to start our timeline at 7 AM, and our timeline has 13 buckets.
The easiest rule of thumb is to include an empty time bucket to the left of your timeline.
Example 1: Peak Volume
Let’s continue with our example of 10,000 hits per day.
Let’s say that most traffic is expected to hit the servers between 8 AM and 8 PM, or a total of 12 hours.
We want to calculate the peak volume, which should occur at noon if we assume an elliptical distribution.
V = 10,000 hits
t = 12 time slots + 1 extra = 13 total
p = (4 * V) / (pi * t)
p = (4 * 10,000) / (3.1416 * 13)
p = 40,000 / 40.84
p = 980 hits during the noon hour, or 16 to 17 hits per minute.
If each session requires 15k of RAM, and is expected to last, on average, 2 hours, then we need to account for slightly more than double the number of peak sessions, which works out to about 29 meg of RAM required.
Again, assuming that due to the long, average session length, you’ll have 100% carryover sessions between 11 AM and noon, you have to provide resources for 1,960 sessions.
Let’s say that your app is really CPU-intensive, and each session takes 1.2% CPU. That’s 2,352% — meaning that you need roughly 24 CPU cores total, to support your application. This might be a single machine with 4 physical CPUs and 6 cores per socket (24 cores) or it might be 6 virtual machines with 4 virtual CPUs per instance, or some other combination that makes sense.
Now we have a sizing baseline for our application!
Estimating Volume at a Given Time Slot
Beyond calculating peak volume, we can use the same distribution curve to figure out what our volume v will be at any given time, t1.
The formula for a circle is:
r^2 = x^2 + y^2
- R is the fixed radius of the circle
- X is the location left or right of the origin (coordinate 0,0)
- Y is the location above or below the origin
Recall that an ellipse is a distorted circle:
( x^2 / b^2) + (y^2 / a^2) = 1
- A is the vertical radius
- B is the horizontal radius
Solving for y:
(y^2 / a^2) = 1 – (x^2 / b^2)
y^2 = a^2 (1 – x^2 / b^2 )
For simplicity, let’s skip the associative distribution of a^2
y = SQRT( a^2 (1 – x^2 / b^2 ) )
Let’s substitute some variables:
- Y is our volume v at a specific time.
- A is equal to our peak volume, p
- B is equal to 1/2 * t (the length of our timeline)
- X is a bit tricky.
- A specific time bucket t1 is the clock time ct1 minus the beginning of the timeline, ct0. We said that our timeline runs from 8 AM to 8 PM, but we added an extra bucket at 7 AM, so we would take a specific time ct1, and subtract the start of our timeline, 7 AM (ct0), to get the time bucket t1 (number of hours since 7 AM)
- The horizontal center of our ellipse is t/2, so we have to subtract t/2
- x = HOURS(ct1 – ct0) – t/2
- SQRT is the “square root” function
- HOURS is an imaginary function that converts a clock time in to an integer number of hours — added for simplicity and clarity
Putting it all together:
x = HOURS( ct1 – ct0 ) – t/2
v = SQRT( p^2 (1 – ( x^2 / (t/2)^2 ) ) )
v = SQRT( p^2 * ( 1 – ( 4 * x^2 / t^2 ) ) )
Example 2: Estimating Volume at 2 PM
- ct1 is 2 PM.
- Our timeline starts at 7 AM (ct0)
- p (from our previous example) is 980
- t, our timeline is 13 timeslots
- v is the volume at ct1, for which we’re trying to solve
Calculate X:
x = HOURS( ct1 – ct0 ) – t/2
x = HOURS( 2PM – 7AM ) – 13/2
x = HOURS( 7 ) – 6.5
x = 7 – 6.5
x = 0.5
Calculate V:
v = SQRT( p^2 * ( 1 – ( 4 * x^2 / t^2 ) ) )
v = SQRT( 980^2 * (1 – (4 * 0.5^2 / 13^2 ) ) )
v = SQRT( 960,400 * (1 – ( 0.25 /169 ) ) )
v = SQRT( 960,400 * (1 – 0.0015)
v = SQRT( 960,400 * 0.9985)
v = SQRT( 958,959.4 )
v = 979
This verifies our calculation – at the middle of the curve, our volume matches the peak volume (off by a little due to the integer nature of slicing the curve up in to segments, plus rounding error).
Example 3: Estimating Volume at 5 PM
- ct1 is 5 PM.
- Our timeline starts at 7 AM (ct0)
- p (from our previous example) is 980
- t, our timeline is 13 timeslots
- v is the volume at ct1, for which we’re trying to solve
Calculate X:
x = HOURS( ct1 – ct0 ) – t/2
x = HOURS( 5PM – 7AM ) – 13/2
x = HOURS( 10 ) – 6.5
x = 10 – 6.5
x = 3.5
Calculate V:
v = SQRT( p^2 * ( 1 – ( 4 * x^2 / t^2 ) ) )
v = SQRT( 980^2 * (1 – (4 * 3.5^2 / 13^2 ) ) )
v = SQRT( 960,400 * (1 – ( 12.25/169 ) ) )
v = SQRT( 960,400 * (1 – 0.0725 ) )
v = SQRT( 960,400 * 0.9275 )
v = SQRT( 890,771 )
v = 944
Analysis
Given the examples above, here is a graph covering 7 AM to 8 PM
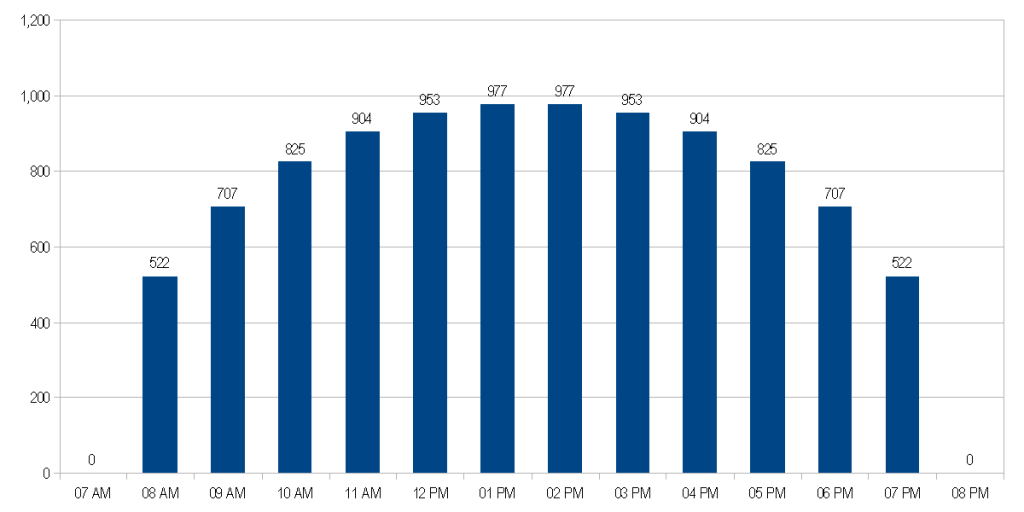
Adding up each bar value, the total is 9,775 – not quite the total 10,000. The reason for the discrepancy is because we are making 13 discrete slices, of what is really a fluid curve. If we increase the number of slices, we will eventually approach our total hit count of 10,000.
This approach assumes that people jump in right at 8 AM to start using the system, and no new sessions come in after 8 PM. In reality, you could add some margin to the timeline – for example, 15 minutes on each end, to account for early birds and stragglers.
t = 13.5
We have 12 time buckets, plus 1 extra time bucket, plus we’re adding 1/2 hour to the timeline.
If we do this, we’re moving the start of the graph BACK 15 minutes, so we need to add that back to X, to keep the center at 0:
t1 = HOUR( cp1 – cp0 ) – t/2 + 0.25
The 15 minute offset shifts the traffic 15 minutes to the left.
With the slightly longer timeline, but the same amount of volume, recalculating p with a timeline of 13.5 instead of 13 results in:
p = 943
Here is what the hit graph looks like, if users start accessing the system at 7:45 and new sessions end at 8:15:
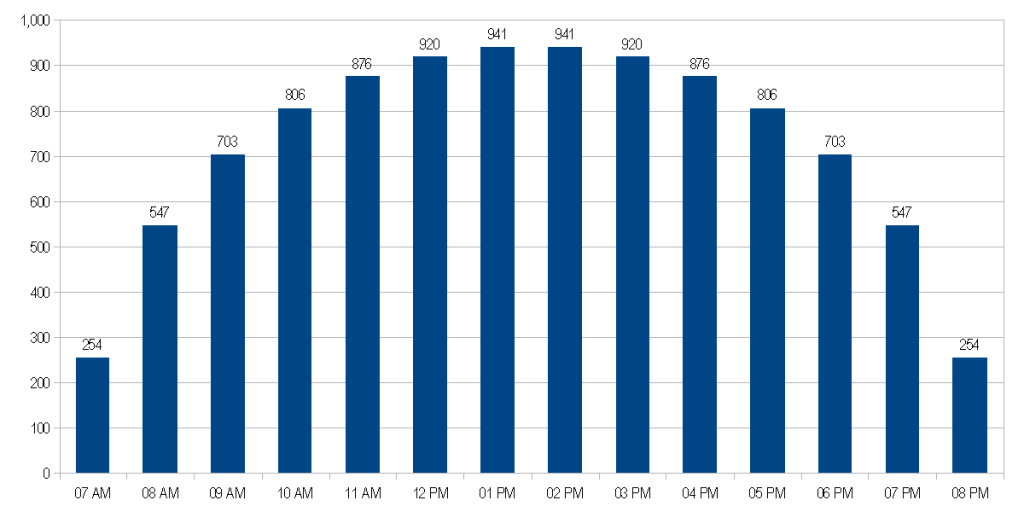
This graph looks much more realistic, and the total number of hits is 10,093 — much closer than the original hit count.
Keep in mind – this is the hit count, which equates to when the user logs in to BEGIN their session. If we said that each session lasts about 2 hours, then each bar on the utilization graph needs to account for sessions that started in the previous 1 hour time frame:

Meaning, you’ll have active sessions until the last user logs out, just after 9 PM.
However, if your application is something that users check infrequently throughout the day, a session might last 10 minutes, meaning that your utilization (session count) would be about 1/6 of the hit count:
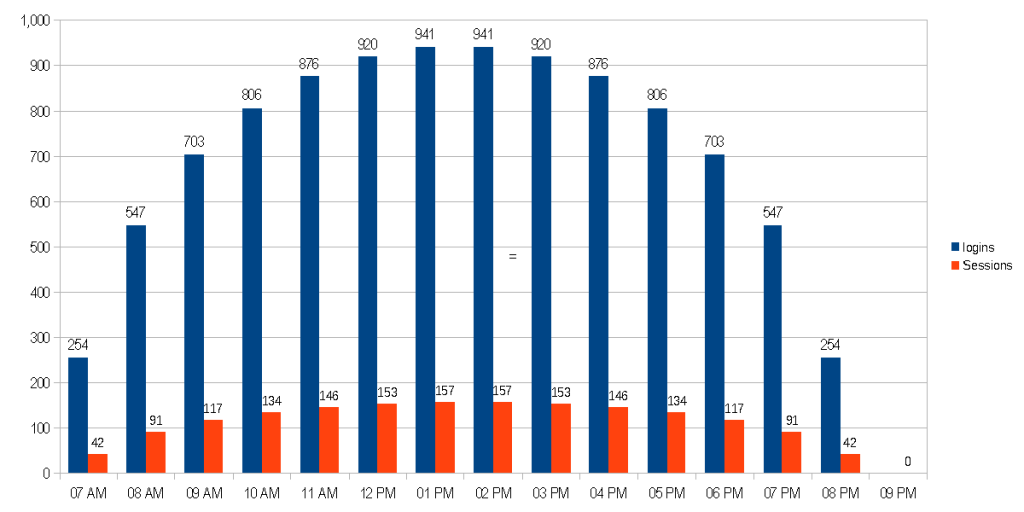
Let’s say that people tend to use the application closer to end of day, say closer to 5 PM. By modifying X, we can create skewed ellipse.
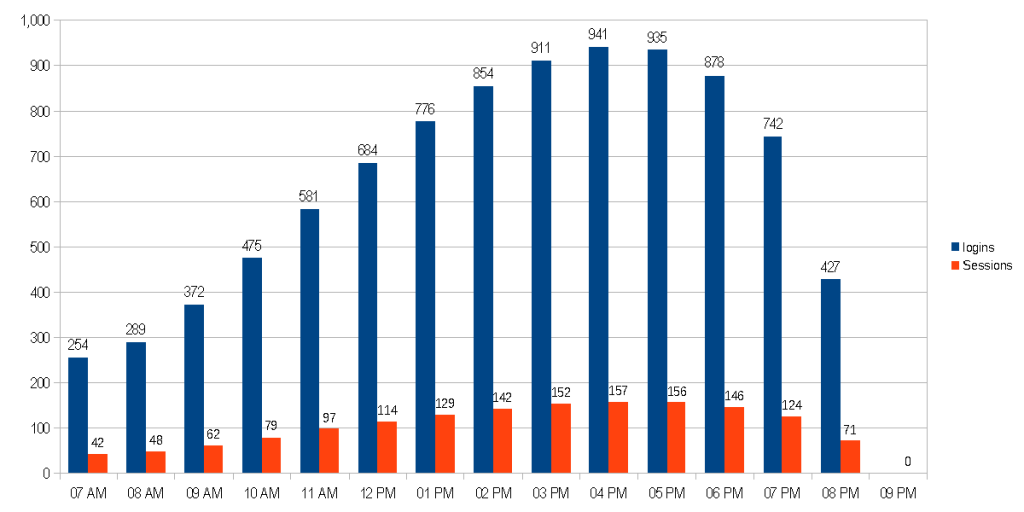
This looks very similar to our cosine curve!
In the graph above, we used the exact same formula for v (the height of each bar), but modified x as follows:
x1 = HOURS(ct1 – ct0)
The old formula would look like this:
x = x1 – t/2 + 0.25
We create exponential growth using x1 compared to t:
x = x1^2 / t – t/2 + 0.25
Since x1 approaches t, this creates an inverse-squared relationship, condensing or skewing the data points toward the right side of the graph.
The exponent 2 can be used to control the rate of skewing. x1^2.5 / t^1.5, for example produces an even more skewed curve. Note that we had to raise t to the power of 1.5 – this keeps the resulting number, although shifted, within the range of the original timeline’s x values.
Also, if you add up the number of bars, the total is only 9,117 – nearly 1,000 data points have been “compressed out” of our curve! The easiest way to compensate for this is to multiply p (our peak volume guestimate) by some fixed number, such as 1.1. If you were to do this, p becomes 1,037, and the sum of the bars equals 10,029 – right back in the correct ball park.
Summary
The best way to predict usage and resources is to look at actual data.
However, if you don’t have live data, because the system is new, or no historic data is available, the best way to predict utilization and resources is to use a distribution curve.
Distribution curves can help you predict:
- Utiliation in terms of concurrent sessions
- Logins for a given time period
- Peak utilization
- Peak computing resources required
- Peak bandwidth required
- Optimum maintenance windows
Elliptical distribution curves use simple formulas, are easy to understand and manipulate, and can be mapped to real-world usage scenarios.